El reentrenamiento de los LLM para comprender el dominio industrial como Internet público
Enseñando nuevos trucos al perro
La emoción e innovación que rodea a la IA generativa y a los modelos de lenguaje grande (LLM) como ChatGPT generan la expectativa de un momento de transformación digital industrial comparable al iPhone. Estos LLM son el resultado del entrenamiento de un modelo de aprendizaje automático con un gran corpus de datos de texto para generar y comprender lenguaje natural. Este salto sin precedentes en el procesamiento de lenguaje natural permite que los sistemas de IA generativa consuman, comprendan y brinden información sobre contenido accesible.
Gracias a su preentrenamiento en tareas de PNL, los LLM cuentan con una amplia base de conocimiento. Sin embargo, el contenido en las bases de datos de los LLM puede estar desactualizado (es decir, anterior a sep. de 2021) y basarse únicamente en contenido del dominio público. Esto puede limitar los datos fuente disponibles para generar una respuesta y potencialmente conducir a información desactualizada o respuestas 'creativas' para compensar la brecha de información (alucinaciones). Si podemos 'entrenar' un LLM como ChatGPT en datos industriales curados y contextualizados, entonces podríamos hablar con estos datos tan fácilmente como lo hacemos con ChatGPT y tener confianza en la base de la respuesta.
El contexto importa
El vasto conjunto de datos utilizado para entrenar los LLM se cura de diversas formas para proporcionar datos limpios y contextualizados. Los datos contextualizados incluyen relaciones semánticas explícitas dentro de los datos que pueden afectar enormemente la calidad de los resultados del modelo.
Contextualizar los datos que proporcionamos como entrada a un LLM asegura que el texto consumido sea relevante para la tarea en cuestión. Por ejemplo, al solicitar a un LLM que proporcione información sobre activos industriales en funcionamiento, los datos proporcionados al LLM deben incluir no solo los datos y documentos relacionados con esos activos, sino también las relaciones semánticas explícitas e implícitas entre diferentes tipos y fuentes de datos.
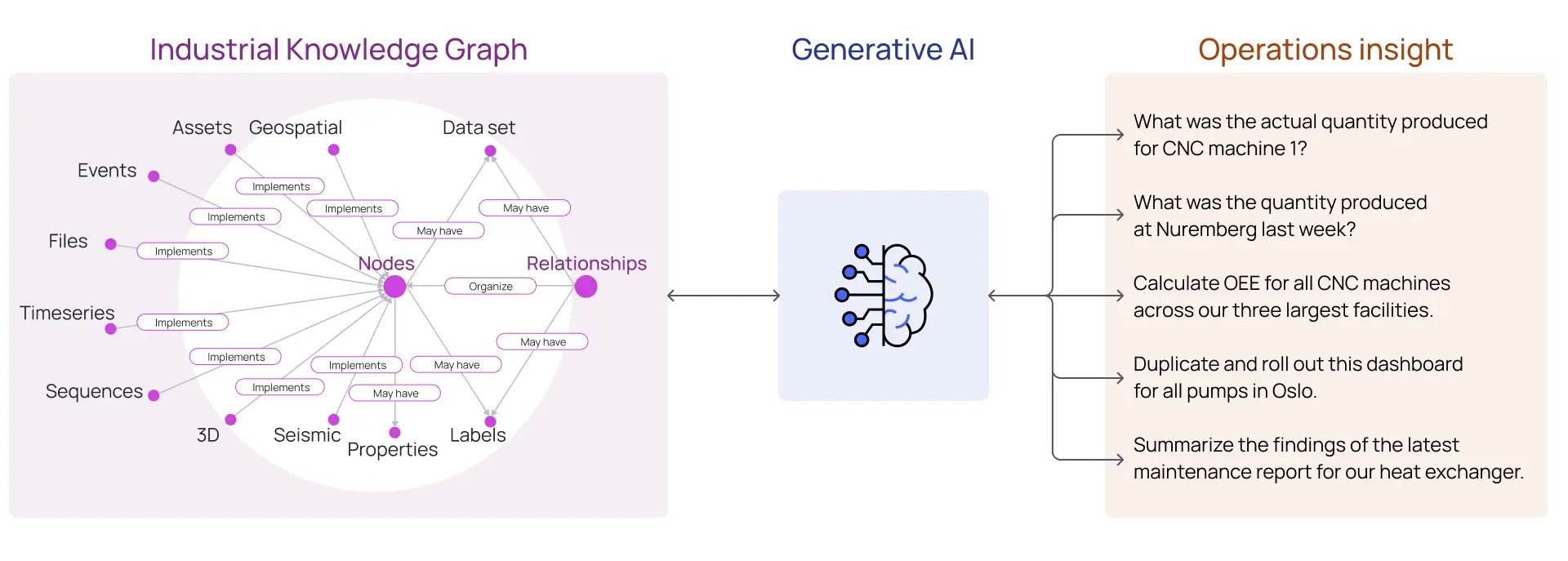
Comprensión de las operaciones a través de un grafo de conocimiento industrial y IA generativa
En el proceso de construcción del grafo de conocimiento industrial contextualizado, los datos también se procesan para mejorar la calidad mediante la normalización, la escalabilidad y el aumento de atributos calculados o agregados. Para la IA generativa, se aplica el viejo dicho de "basura entra, basura sale". Las agregaciones de datos industriales en grandes almacenes de datos y lagos de datos que no se han contextualizado o preprocesado carecen de las relaciones semánticas necesarias para "comprender" los datos y carecen de la calidad de los datos necesaria para que los LLM proporcionen respuestas confiables y deterministas.
¿Cómo 'enseñamos' datos industriales a un LLM?
Un LLM se entrena dividiendo los datos de texto en colecciones más pequeñas, o fragmentos, que se pueden convertir en embeddings. Un embedding es simplemente una representación numérica sofisticada del 'fragmento' de texto que tiene en cuenta el contexto de la información circundante o relacionada. Esto permite realizar cálculos matemáticos para comparar similitudes, diferencias y patrones entre diferentes 'fragmentos' para inferir relaciones y significado. Estos mecanismos permiten que un LLM aprenda un lenguaje y comprenda nuevos datos que no ha visto previamente.
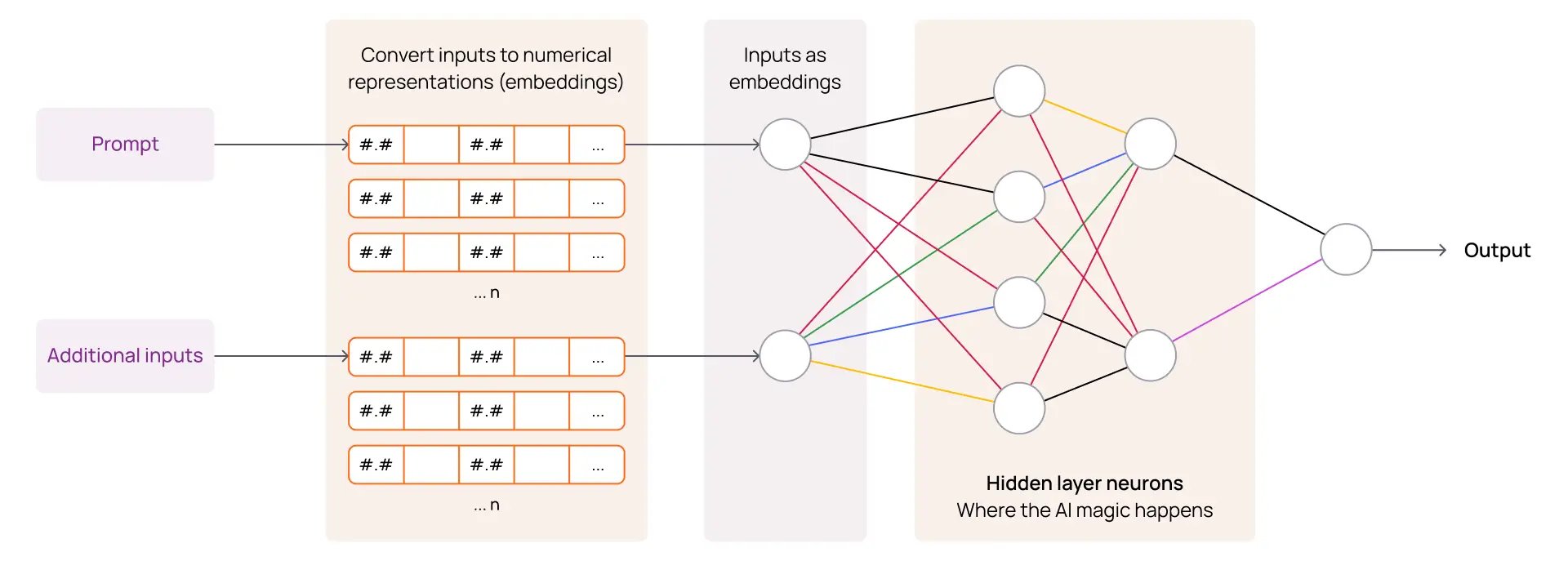
De la entrada a la salida con IA generativa para la industria
Cuando le hacemos una pregunta (indicación) a un LLM y le proporcionamos información adicional para que la considere al responder (entradas), procesa la indicación codificándola en estas representaciones numéricas utilizando las mismas técnicas utilizadas durante el entrenamiento. Esta representación numérica de la indicación se compara matemáticamente con los embeddings almacenados que el LLM ya 'conoce', junto con los embeddings codificados para cualquier contenido adicional proporcionado con la indicación (entradas). El LLM recuperará los embeddings ('fragmentos') considerados relevantes y luego los utilizará como fuentes para generar una respuesta.
Opción 1: El enfoque de CoPilot
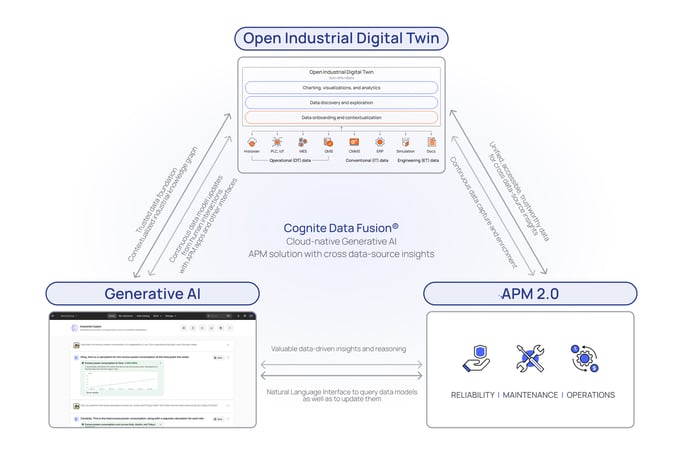
Un Digital Twin Industrial Abierto cobra vida con un completo y contextualizado grafo de conocimiento que abarca todos los datos industriales relacionados con un activo. Al capturar tanto los datos del activo como las relaciones semánticas entre los diferentes tipos y fuentes de datos del activo, se vuelve posible construir una robusta biblioteca de API que pueda navegar e interrogar de forma programática el Digital Twin del activo.
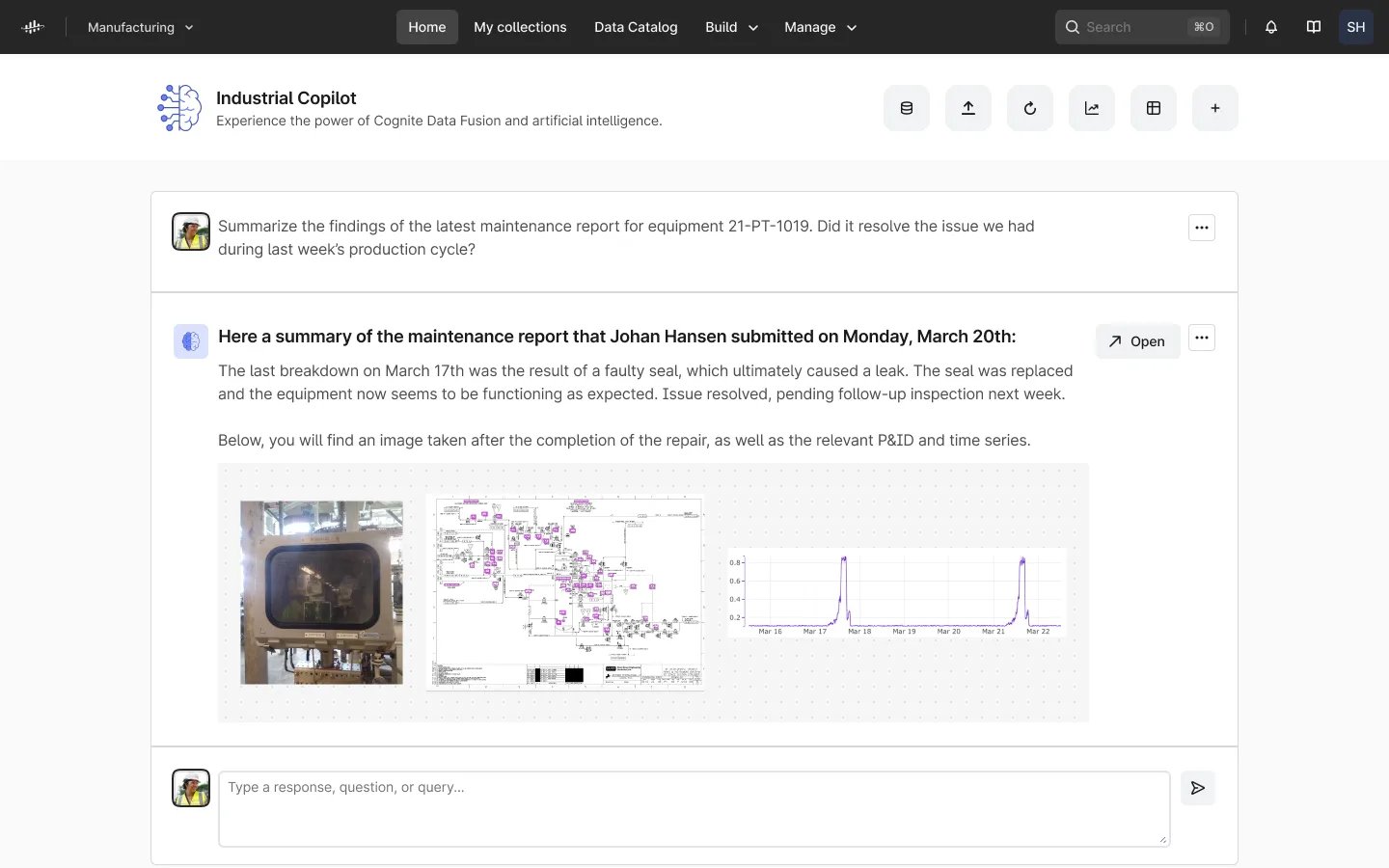
Dado que los LLMs como ChatGPT comprenden y pueden generar código sofisticado en varios lenguajes (por ejemplo, Python, JavaScript, etc.), podemos darle una indicación al LLM sobre nuestros datos industriales, y él puede interpretar la pregunta, escribir el código relevante utilizando las API de Cognite Data Fusion y ejecutar ese código para devolver una respuesta al usuario (ver imagen a continuación).
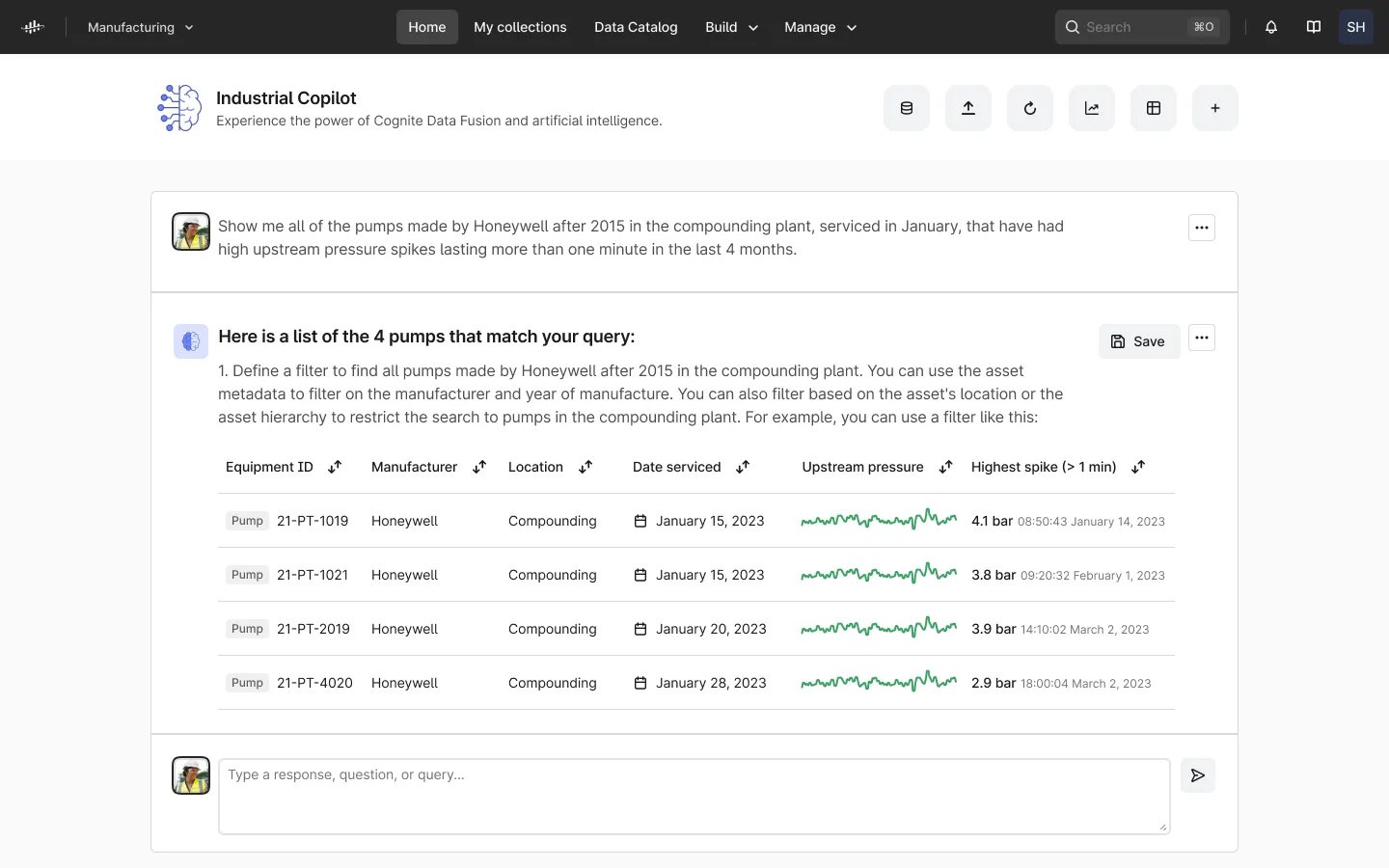
Copiloto Industrial: Búsqueda semántica
Estos enfoques basados en CoPilot aprovechan el poder del lenguaje natural para comprender y escribir código basado en documentación y ejemplos de API publicados. Esto es imposible con los data lakes o los data warehouses, donde, sin un grafo de conocimiento industrial contextualizado, no existen bibliotecas de API que puedan utilizarse como un mecanismo confiable para acceder a datos industriales ricos. Además, debido a que todo el acceso a los datos se realiza a través de las API, no se comparten datos propietarios con terceros y los mecanismos integrados de registro y control de acceso se mantienen intactos.
Opción 2: Proporcionar datos contextualizados directamente al LLM
Las bibliotecas de API disponibles de OpenAI, langchain y otros nos permiten aprovechar el poder del procesamiento de lenguaje natural del LLM en conjunto con datos propietarios. Estas bibliotecas permiten a los desarrolladores tomar datos que normalmente excederían las limitaciones del texto de entrada de GPT y realizar las mismas tareas que haría un LLM. Específicamente, analizar datos industriales contextualizados en "trozos" que se pueden convertir en embeddings y almacenar en una base de datos privada.
Esta base de datos puede incluir representaciones numéricas (embeddings) de datos de activos específicos, como series temporales, órdenes de trabajo, resultados de simulación, diagramas P&ID, así como las relaciones definidas por el grafo de conocimiento del gemelo digital. Utilizando estas API abiertas, podemos enviar una indicación al LLM junto con el acceso a nuestra base de datos de embeddings propietaria para que el LLM formule su respuesta basándose en el contenido relevante extraído de nuestros propios grafos de conocimiento propietarios.
¿Qué se necesita para comunicarse con los datos industriales a través de la IA generativa?
Un Duplicado Digital Industrial Abierto es un requisito previo para permitir que la IA generativa comprenda y se comunique con sus datos industriales. Los modelos de datos y las relaciones contextualizadas que impulsan el esquema de un duplicado digital hacen posible proporcionar un acceso abierto basado en API a los datos industriales que los LLM, como ChatGPT, pueden utilizar para escribir y ejecutar software en respuesta a una indicación de manera automática.
Además, los datos industriales contextualizados no solo brindan los datos en bruto relacionados con nuestros activos, sino también las relaciones con fuentes de datos adicionales que permiten e impulsan interrogaciones más determinísticas de datos industriales por parte de modelos LLM.
Con la IA generativa impulsada por un Duplicado Digital Industrial Abierto, finalmente podemos ofrecer soluciones de Gestión del Rendimiento de Activos de próxima generación con información de múltiples fuentes de datos. Para ser los primeros en obtener más información, regístrese en nuestro boletín de noticias ahora y manténgase actualizado sobre este tema transformador de rápida evolución.