
Logre una ventaja de datos acumulativa con la poderosa combinación de contextualización, gemelos digitales e IA generativa.
Ahogados en datos
Cuando se trata de liberar datos de sistemas fuente aislados, la mayoría de las organizaciones industriales cometen el error de no pensar más allá de un data lake para resolver el problema de los datos industriales.
Los data lakes son una conglomeración de datos sin transformar y en bruto. Los expertos en la materia aún no pueden encontrar los datos que necesitan, no confían en su calidad y ciertamente no pueden utilizarlos para tomar decisiones de alto impacto.
“Los datos no tienen valor a menos que el negocio confíe en ellos y los utilice.”
Si bien algunas aplicaciones se benefician de los datos en bruto, la mayoría de las aplicaciones, especialmente el desarrollo de aplicaciones de bajo código y sin código, requieren datos que hayan pasado por algún tipo de procesamiento contextual adicional. La "contextualización humana" sigue siendo necesaria, lo cual es factible de hacer con un alcance limitado pero imposible si desea escalar sus inversiones digitales y de datos.
"Nuestro equipo de ingeniería de sitio está realizando la contextualización de datos de forma manual una y otra vez en la actualidad. ¿Cómo podemos automatizar la contextualización de datos para permitirnos hacer varias cosas más rápido, de manera bien gobernada y construyendo sobre el trabajo previo cada vez?" - Ejecutivo de digitalización en una importante empresa de downstream.
"Nuestro equipo de ingeniería de sitio está realizando la contextualización de datos de forma manual una y otra vez en la actualidad. ¿Cómo podemos automatizar la contextualización de datos para permitirnos hacer varias cosas más rápido, de manera bien gobernada y construyendo sobre el trabajo previo cada vez?"
- Ejecutivo de digitalización en una importante empresa de downstream
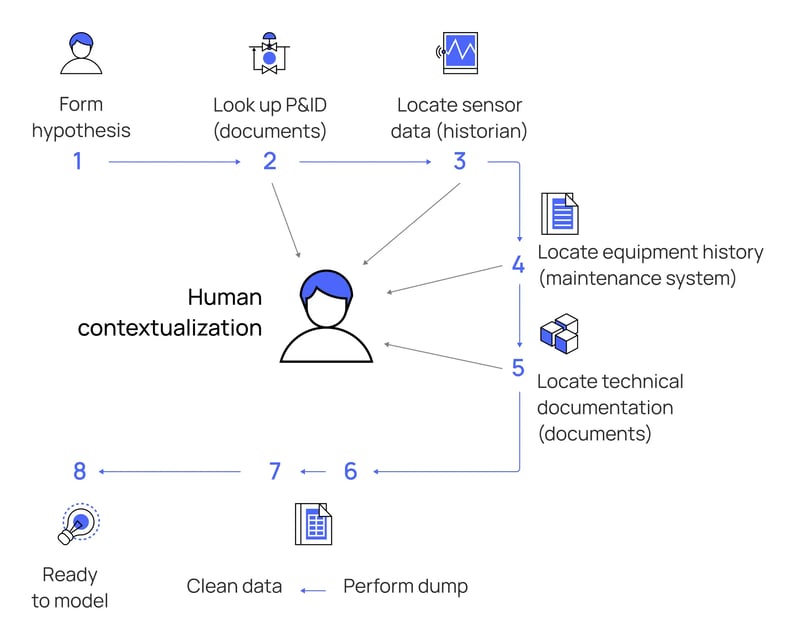 Entonces, ¿qué se requiere para transformar "ciénagas de datos" en refugios de datos contextualizados que impulsan la visión operativa en todos los niveles de la organización?
Entonces, ¿qué se requiere para transformar "ciénagas de datos" en refugios de datos contextualizados que impulsan la visión operativa en todos los niveles de la organización?
Salvados por el contexto
La contextualización es el proceso de identificar y representar las relaciones entre los datos para reflejar los vínculoss que existen entre las fuentes de datos en el mundo físico. La capacidad de construir estas relaciones y poblar un conocimiento gráfico industrial es fundamental para una estrategia de datos exitosa. Es este conocimiento gráfico industrial el que sirve como base de un Digital Twinl Industrial Abierto.
Un Digital TwinIndustrial Abierto es la aplicación más poderosa y práctica de la contextualización de datos. Los Digital Twinss son herramientas fantásticas para comunicar el valor potencial, mejorar las actividades diarias, agilizar los flujos de trabajo y descubrir más oportunidades y soluciones cuando están impulsados por datos liberados, enriquecidos y contextualizados.
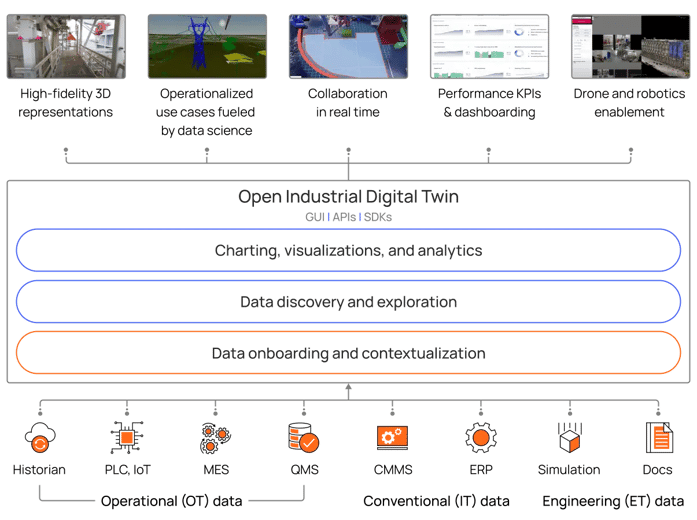
No todos los Digital Twins son iguales. Tanto las personas como la inteligencia artificial dependen de datos en los que pueden confiar. Obtenga más información sobre por qué Cognite Data Fusion logra la primera certificación de cumplimiento DNV para Digital Twins y cuenta con garantía de calidad para su uso en organizaciones industriales del mundo real.
Los datos contextualizados generan un valor comercial inmediato y ahorro significativo de tiempo en muchas aplicaciones de optimización del rendimiento industrial, así como en los flujos de trabajo de análisis avanzado. Además, el acceso a datos contextualizados permite que los expertos en la materia adquieran más confianza e independencia al tomar decisiones operativas o al trabajar en casos de uso con científicos de datos e ingenieros de datos.
La contextualización ayuda a resolver la complejidad de los datos industriales, pero una vez hecho esto, la pregunta es, ¿cómo utilizamos luego estos datos? La IA generativa cambiará la forma en que los consumidores de datos interactúan con ellos, mejorando el autoservicio y posiblemente eliminando algunos flujos de trabajo que requieren intervención humana, pero ¿podrá eliminar por completo la "contextualización humana"?
Potenciado por la IA generativa
La IA generativa, como ChatGPT/GPT-4, tiene el potencial de acelerar la transformación digital industrial.
Mientras que un ingeniero de procesos podría pasar varias horas realizando "contextualización humana" (a un costo por hora de $140 o más) de forma manual, una vez más, los grafos de conocimiento industrial contextualizados proporcionan las relaciones de datos confiables que permiten a la IA generativa navegar e interpretar con precisión los datos para los operadores sin necesidad de habilidades de ingeniería de datos o codificación.
Sin embargo, aunque la IA generativa puede ayudar a que sus datos "hablen como humanos", no necesariamente hablará el lenguaje de sus datos industriales. Se requiere una sólida base de datos industriales para eliminar el riesgo de "alucinaciones", es decir, respuestas incorrectas o no justificadas por los datos de entrenamiento del AI.
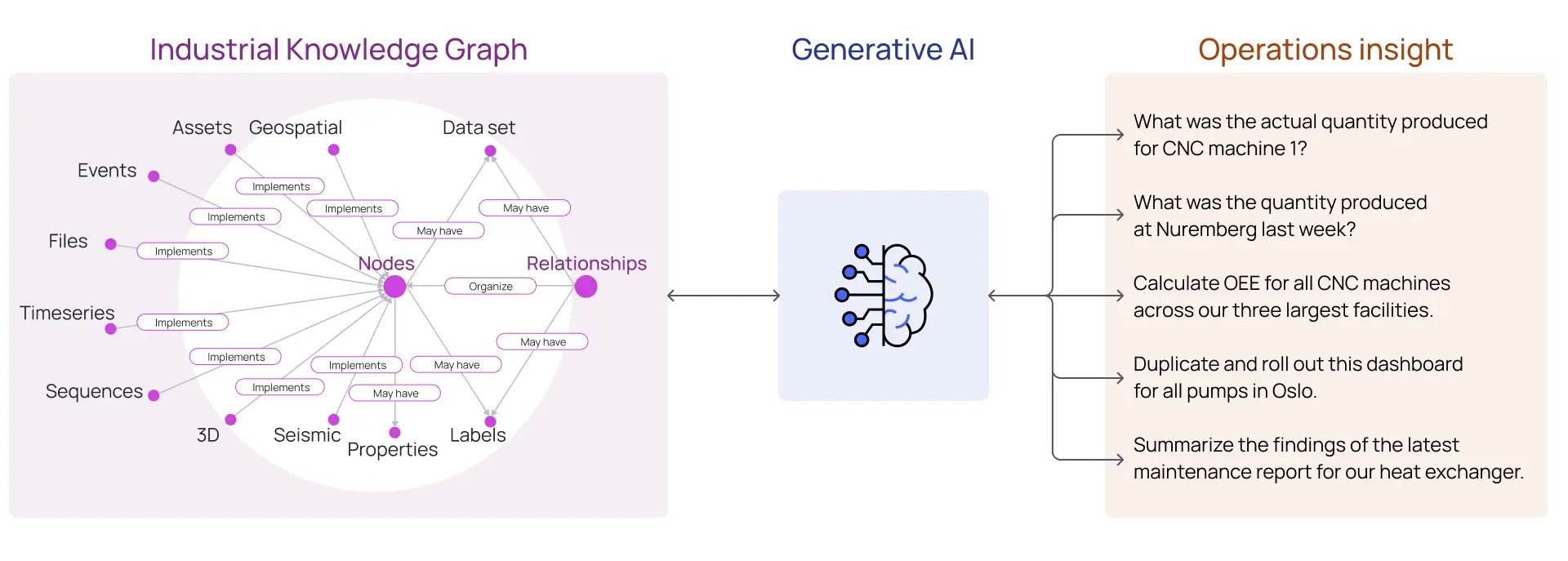
Por eso, un Open Industrial Digital Twin es un requisito previo necesario en cualquier estrategia digital que incorpore IA generativa. Un digital twin proporciona el grafo de conocimiento industrial, que sirve como base confiable para que las tecnologías de IA generativa formen una comprensión precisa de la realidad industrial de su organización. Como resultado, las personas en toda la empresa pueden obtener con confianza información valiosa sobre las operaciones.
Lo que antes llevaba horas de tiempo preciado a sus ingenieros de procesos, trabajadores de mantenimiento y científicos de datos ahora solo tomará unos segundos con la búsqueda semántica impulsada por IA generativa
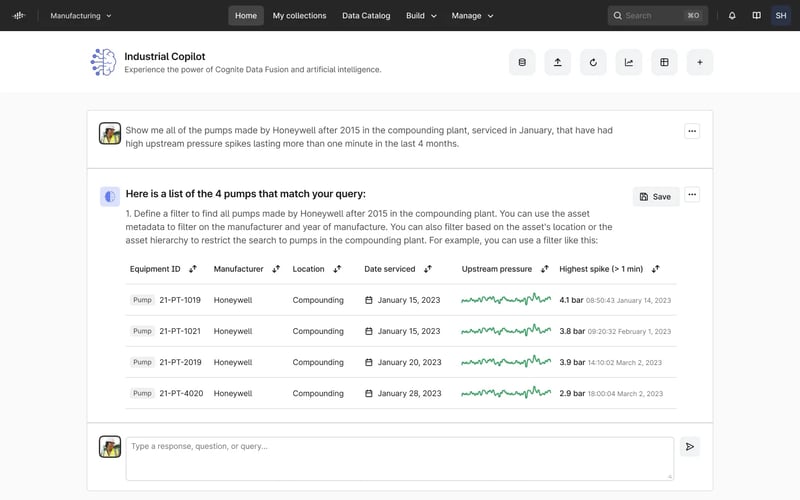
La visión a través de múltiples fuentes de datos es más valiosa que la visión de una sola fuente. Permite que las personas en todos los niveles de una organización industrial obtengan una comprensión completa de las operaciones y procesos del mundo real. Esto conduce a mejores conocimientos, decisiones más rápidas y un retorno de la inversión de tres dígitos. En particular, esta visión a través de múltiples fuentes de datos es poderosa para la Gestión del Rendimiento de Activos, que inherentemente abarca los dominios de mantenimiento, operaciones y confiabilidad.
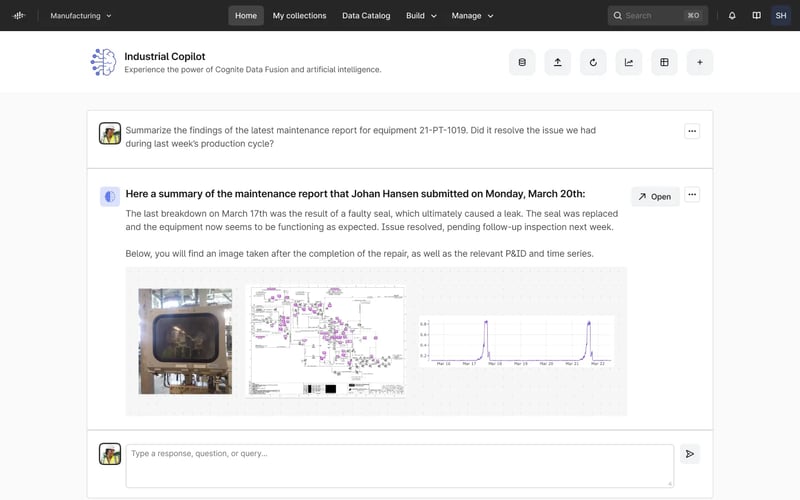
Una ventaja de datos acumulativa
Si bien la contextualización impulsada por la IA es convincente, el verdadero poder de las nuevas tecnologías de IA generativa radica en su capacidad para codificar la experiencia humana mediante la creación de datos nuevos y mejores.
Ya hemos visto cómo GPT-4 de OpenAI y Codex pueden convertir a cualquier persona en programadores competentes, sin necesidad de experiencia previa. Impulsados por esta tecnología, los expertos en la materia, aquellos que poseen el mayor conocimiento industrial pero carecen de experiencia en programación, pueden crear series de tiempo calculadas, construir paneles de control, generar código y mucho más. Convirtiendo su relación de décadas con los equipos y los procesos de producción en conocimientos que abarcan múltiples fuentes de datos y que se escalan con el golpe del teclado.
A medida que más personas utilizan y enriquecen el gemelo digital industrial abierto, la cantidad y variedad de datos en el gemelo digital se vuelve más rica y valiosa que todas las demás fuentes de datos combinadas.
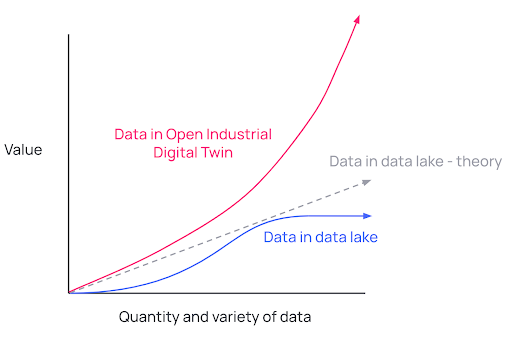
Al igual que el principio del interés compuesto, los datos en el Gemelo Digital Industrial Abierto se vuelven cada vez más valiosos a medida que más personas utilizan, aprovechan y enriquecen esos datos. Datos más valiosos y de alta calidad conducen a ideas más poderosas. Ideas más poderosas en las que los consumidores de datos pueden confiar conducen a mayores niveles de adopción en toda la empresa. Y una experiencia amigable con la IA garantiza que la adopción y el uso continúen, y este ciclo se repita a una tasa creciente de manera exponencial.
En un Data Lake, existe una relación más lineal entre la cantidad de datos que se ingresan y el valor adicional que el contexto añadido proporciona. Este valor a menudo se estabiliza después de cierto punto, incluso cuando se ingresan datos adicionales. El verdadero valor acumulativo radica en la capacidad de los nuevos datos para enriquecer los datos ya existentes, mejorar la calidad general de los datos y las relaciones, y, en última instancia, generar ideas confiables y accionables.
En Cognite, creemos que las ideas más valiosas se logran al poner todos sus complejos datos industriales en contexto y facilitar que las personas accedan, utilicen y enriquezcan esos datos.