産業界でAIユースケースをスケールするコンテキスト化エンジンについて
Cogniteでは、コンテキスト化について多くの質問を受けます。特に次の2点について質問を受けます。
- Cogniteのコンテキスト化エンジンは実際どのように機能するのか。
- コンテキスト化によって、どのようにユースケースのスケーリングが桁違いに効率化されるのか。
本記事では、この2つの質問に答え、最後にデータのコンテキスト化と現代のデータマネジメントにおけるその役割について「エグゼクティブサマリー」を提示します。さあ始めましょう。
おすすめ記事:データの統合で欠かせない「コンテキスト化」とは?活用例も紹介!
Cogniteのコンテキスト化エンジンはどのように機能するのか。
まず、基本事項をいくつかおさえておきましょう:
- 理想的で普遍的なデータモデルは存在しません。定義済みの参照データモデル(適用可能であれば業界標準に基づいていてもよいですし、または参照としてアセットの階層のみを利用してもよいでしょう)があると有効です。このようなデータモデルは、参照モデルからアプリケーションまたはユースケースに固有のデータモデルへのより効率的なマッピングをサポートするからです。参照データモデルを構築するステップは、再利用可能なデータアセットの始まりを意味するため、データアーキテクチャ内でソースからアプリケーションへデータを移行する際の標準的な要素であるべきです。
- AIやMLを使ってもコンテキスト化で何でもできるというわけではありません。異なるデータセットを正常に照合し、参照データモデルとアプリケーションデータモデルに追加するには、マッチングシグナルが存在しなければなりません。マッチングシグナルが弱い場合でも、中小企業に集中しがちなデータコンテクスト化作業を、構造化し管理するというデータコンテキスト化エンジンの強力な利点は残っています。いかなるシナリオでもExcelのワークシートを利用する価値はありません。
- お客様のデータは生きています。コンテキスト化ソリューションはこれを反映する必要があります。コンテキスト化作業を手作業でしたくはないでしょう。
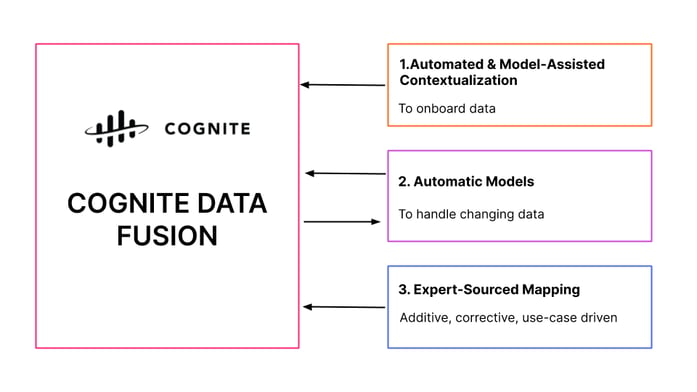
Cognite Data Fusionでコンテキスト化は2つの互いに補完しあうレベルで行われます:
- ソースのシステムデータセットを参照データモデルと関係づけ、相互に関係づけるための水平コンテキスト化
- 特定のユースケースのデータスキーマを対象とするテンプレートを自動補完することによる垂直コンテキスト化
水平コンテキスト化は、データ統合プロセスの一部として(下のスクリーンショットを参照)、リソースのマッチング、P&ID変換、非構造化ドキュメントのコンテキスト化を扱います。垂直コンテキスト化では、すでに実行されている基本となる水平方向のデータセットのコンテキスト化に加え、パターン認識と強化学習を使用し、大規模にユースケースのデータスキーマを自動補完するためにテンプレートを使用します。
Cognite Data Fusionは、水平コンテキスト化のための組み込み継続学習機構とともに、学習済のMLベースモデル、カスタムMLベースモデル、ルールエンジン、手動またはエキスパートによるマッピングを組み合わせて使用します。変化するデータを扱うために自動モデルが適用されます。
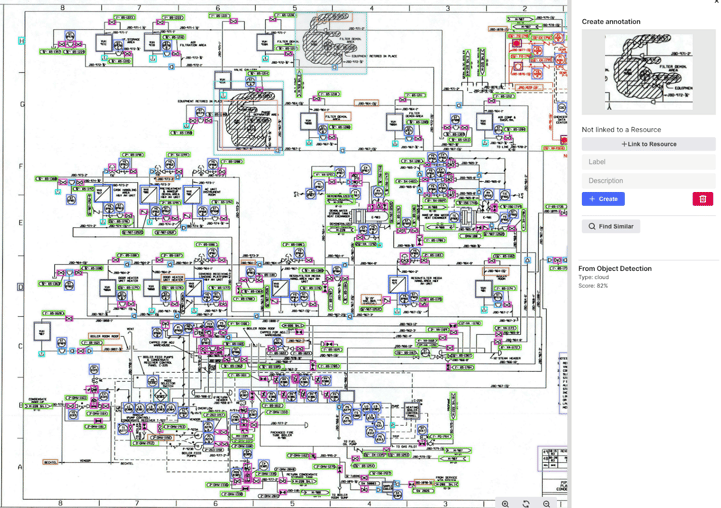
P&IDコンテキスト化(下のスクリーンショットを参照)のためのコンピュータビジョンとNLPアプリケーション分野、非構造化ドキュメントのコンテキスト化について詳しく説明しませんが、非構造化ドキュメントからリッチなメタデータを持つ構造化ドキュメントへの変換は、Cognite Data Fusionの水平コンテキスト化機能に組み込まれています。メタデータについては、結果の構造化されたデータラベルとデータリレーションシップの両方が、すべてリッチで強力なメタデータを構成しています。このようなメタデータは、現代のデータ活用シナリオで、ほぼすべての形態の自動化と拡張の鍵になります。
おすすめWEBセミナー:https://www.cognite.com/ja-jp/blog/cognite-data-fusion-roadmap-webinar
コンテキスト化によってどのようにユースケースの拡張が桁違いに効率化されるのか
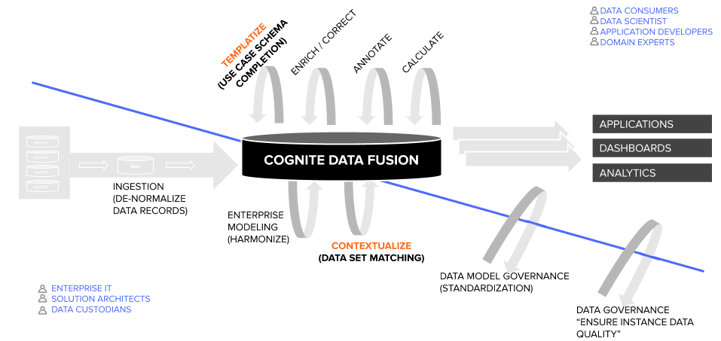
参照データモデルが定義されたら、ユースケースの実行と拡張に進みます。参照データモデルを定義するステップは、個々のユースケースの開発またはスケーリングに取り組む上で必須ではありませんが、再利用可能なデータアセットの作成の始まりを意味するため、このステップに従うことをおすすめします。
下の図は、データエンゲージメントプロセスの2つの「領域」がいかに相互に依存しているかを表しています。対角線の下は、水平コンテキスト化が行われる領域です。対角線の上は、ユースケースの解決が行われる領域です。ここで垂直コンテキスト化が行われます。垂直コンテキスト化とは、特定のユースケーススキーマを対象とするテンプレートを自動補完することです。
ここでも詳しい説明は省略しますが(Cognite Data Fusionの製品デモを申し込んでください)、Cognite Data Fusionのカスタマイズ可能なテンプレートまたはカスタムテンプレートをそのまま使用すると、ユースケーススキーマが完成します。データテンプレートと、関連するAIによって作られた提案は下のスクリーンショットで確認できます。
テンプレートを使うことで、 従来のMDMアプローチのような大規模なセンサーデータと比べ、たとえば各時系列のセンサーデータストリームは、個々のデータ品質をモニタリングできるようになり、カスタムメイドのデータ品質要件をユースケース自体に関連づけます。
ユースケースのテンプレートも同様に強力です。すべてのデータロジックを含むアプリケーションの複雑さの多くをデータレイヤーで直接カプセル化し、たとえばデータの可視化では数時間で1つのダッシュボードから1000のダッシュボードにスケールします。すべてのデータテンプレートはもちろんNotebookからもアクセスでき、プログラムで使用できます。
-png.png?width=721&name=Choke-Valve-Cognite-Data-Fusion%20(2)-png.png)
データコンテキスト化は現代のデータマネジメントの中核
産業に特化したコンテキスト化エンジンは実際どのように機能するのか、コンテキスト化によって産業におけるユースケースの拡張を桁違いに効率化するのか理解していただけたことでしょう。
-png.png?width=721&name=Gartner%20-%20quote%20(2)-png.png)
最後に、データのコンテキスト化による自動化されたデータマネジメントの役割と価値について「エグゼクティブサマリー」を記載します。
- データを管理するデータと分析の責任者には、迅速かつ低コストでプロジェクトを遂行することが求められ、データソースから大規模なアプリケーションまで、データの流れ全体で自動化の需要が高まっています。
- AIとMLで拡張することで、従来のMDMのように手作業でデータに単一構造を設定するのではなく、データから複数の多様な構造や洞察が生まれ、アクティブなメタデータが作成されます。アクティブで、動的に推論され、信頼のおけるメタデータは、データを理解しやすく有用なものにするための共通の道筋であり、重要な成功要因です。
- データのコンテキスト化はIT部門だけのものではありません(データプラットフォームのバックエンド性能など)。データのコンテキスト化は、問題解決とスケーリングの両方に必要不可欠で、シチズンデータサイエンスプログラムの成功に欠かせません。
本記事はいかがでしたか。ぜひみなさまのご意見や体験をお聞かせください。
Cogniteとは
Cogniteは、2016年にノルウェーで設立され、世界中の製造業や石油ガス、電力などの重厚長大産業の本格的なデジタルトランスフォーメーションをサポートするグローバルな産業用SaaS企業です。主要製品であるCognite Data Fusion (CDF)は、OT/ITデータの民主化とコンテキスト化を通じて、安全性、持続可能性、効率性を向上させ、収益を向上させる産業用アプリケーションを推進します。
Cognite株式会社は、Cogniteの100%出資子会社として2019年11月に設立され、Cogniteの主力製品となるCognite Data Fusion(CDF)の国内における販売、マーケティング、およびサポート拠点となっております。
