デジタル成熟度から産業変革へ
すべての産業組織にとって、運用技術(OT)システムで生成されたデータのインテリジェントな使用は、オペレーショナルエクセレンスを高めるための中心的な取り組みです。したがって、デジタルトランスフォーメーション、データの使用、スケーリング、価値実現までの時間を誰もが話題にしている一方で、産業界で実際に利益を得ている企業はほとんどありません。
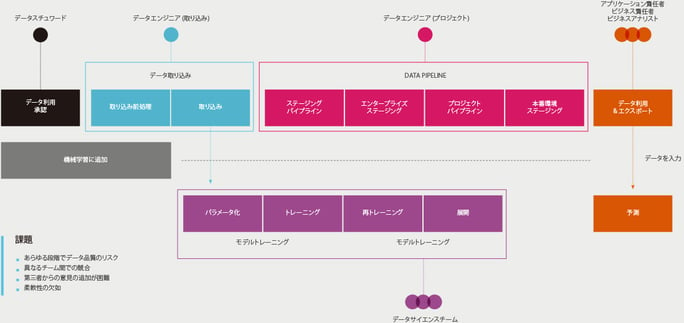
また、課題となるのはデータではありません。OTのデータは、組織がさらに効率的で回復力の高い運用を構築し、従業員の生産性と顧客満足度を高めるための素材です。このOTデータは豊富にありますが、産業組織はますますつながっていく運用から価値を生み出そうと奮闘しています。IDCが示すところによると、データを分析し、そのデータからかなりの程度まで価値を引き出している組織は4社中1社にとどまるとのことです。
適切なツールとプロセスがないというのは、相当に支障を来します。その結果として、データ作業者が自分の時間のほぼ90%をデータの検索、準備、管理に費やすことになります。データの価値を失うという不安から、組織は往々にしてデータの整理よりもデータの集中化を優先してきました。その結果、思慮を欠いた「データスワンプ」が生じ、不明瞭でコンテキスト化されていないデータの問題だけがいつまでも残ることになったのです。
機械学習(ML)を導入して予測アルゴリズムを開発した企業は、信頼できる品質のデータを持つことがいかに重要であり、ヒストリカルデータが常に信頼できるわけではないということをすぐに理解しました。また、データドリブンのイノベーションをサポートするにはデータガバナンスが必要ですが、多くの組織は、その実現に必要な要件に対応できていません。
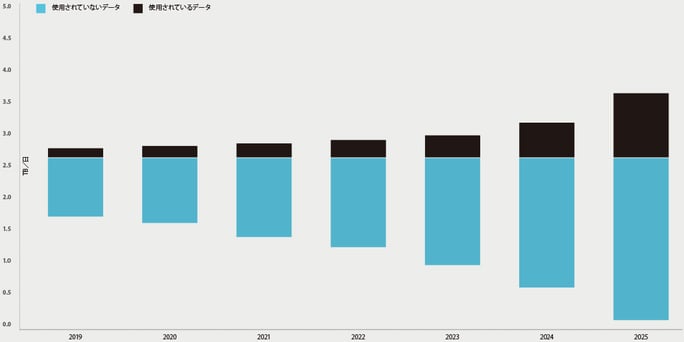
実際には、運用アセットがさらに複雑さを増し、つながり、インテリジェントになり、さらに多くのリアルタイム情報も提供するようになるにつれて、計画・運用・メンテナンスを可能にするデータドリブンの意思決定がますます複雑になっています。これを大局的な視点から考えると、製造、石油・ガス、ユーティリティ、鉱業にわたる組織は、毎日の運用・制御データのスループットが今後12か月間で16%成長すると見込んでいます。マーケットインテリジェンスプロバイダーであるIDCは、これらの組織のサイロ全体にわたる運用によって毎日生成されるデータを測定しており、産業分野全体のデータとその使用の将来的な拡張をモデル化しています。運用のデジタル化が拡大していることを考慮しても、2025年にはこのデータの約30%しか十分に活用されないとIDCは予測しています(図5)。