“DataOps is the ability to enable solutions, develop data products, and activate data for business value across all technology tiers from infrastructure to experience.”
Principles of Industrial DataOps
Now we come to the core principles of the novel Industrial DataOps approach. This chapter will lay out a set of essential concepts to guide you on your way to extracting maximum value from your data. Some readers may be familiar with long lists of general DataOps principles, such as those provided in the formidable DataOps Cookbook. (Fig. 10) You may have also seen some of the detailed DataOps evaluation criteria offered by forward-thinking technology consultancies (Fig. 11).

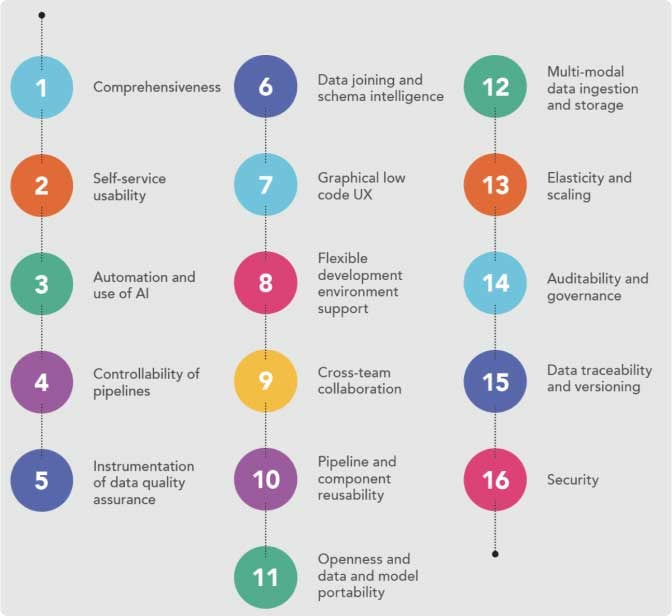
While much of the general DataOps material provides useful background information, the purpose of this book is to provide specific, practical guidance to help organizations in asset-heavy enterprises operationalize data for value.
Since our focus is on Industrial DataOps, the principles we put forward here are squarely from the perspective of digitalization leaders focusing on industrial operations.
7 Principles of Industrial DataOps
1.Don’t Do POCs
POCs are worthless to your CFO. Every digitalization use case you start needs to be architected to run live in production, at scale, before the first line of code is written.
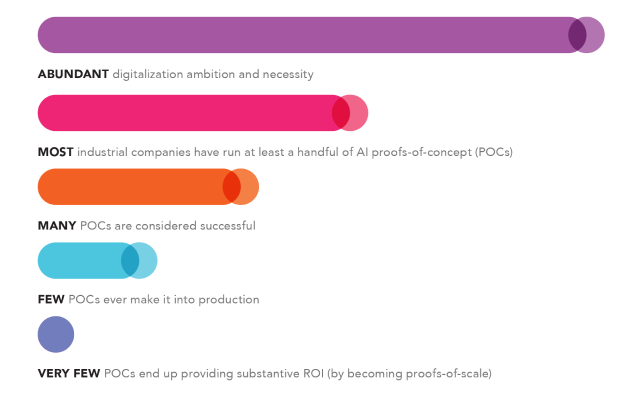
Most of us have been there, or are there right now: in POC purgatory. It’s easy to understand why. Over recent years, we have seen a well intended, though at times obsessive, bottom-up and top-down drive to show digitalization use cases to all industrial enterprise stakeholders, not least to public markets, industry peers, and trade press.
This has unfortunately often resulted in prioritization of easy-to-communicate digitalization showcases rather than actually delivering in-production operational digitalization solutions of real bottom-line value. The optics trap of quick digitalization success has trumped genuine in-production success.
It is important to note in this context that POCs themselves are not to blame. It makes sense to validate use cases before their operational scaling. Challenges, and consequent loss of real value capture, emerge when operational scaling is not intrinsic to the overall digitalization framework, technology architecture, and processes followed. In other words, before a POC is signed off, the execution architecture needs to account for its operational production environment scaling, and not just its theoretical ROI viability.
By implementing digitalization use cases following a systematic platform approach rooted in best Industrial DataOps practices, enterprises can break free of the POC purgatory cycle and focus on use case innovation that delivers in production at scale.
“DataOps is the ability to enable solutions, develop data products, and activate data for business value across all technology tiers from infrastructure to experience.”

2.Think in Data Products, Execute in Data Domains
For data to be operationally useful at scale and for critical operations, it needs to be productized. To productize your data, focus on the most valuable operational data domains first, not on the enterprise-wide master data landscape all at once.
Advances in cloud data storage and elastic processing have catapulted us into the early era of always-on secure data access for all data consumers within and around the enterprise. That said, there remains an exponentially growing need for a similar step change to happen at the intersection of data engineering and custodianship with the business expertise for that data domain.
This shift from data availability to data products as a service (Fig. 13) is what will allow us to transform our data swamps into operational data architectures of real business value.
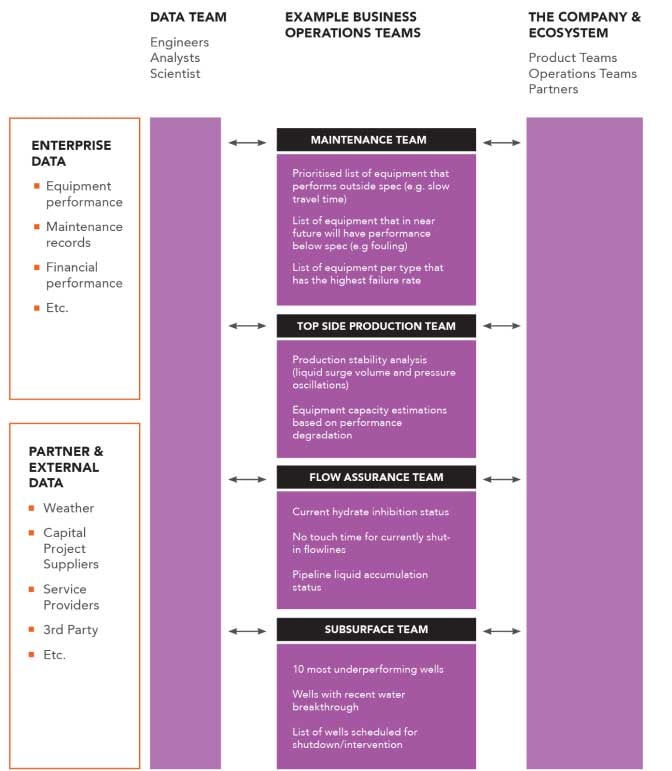
Any organization hoping to successfully transition into offering data products as a service, needs to embrace a shift in data product ownership. The necessary move is from a centralized data team, such as digital or data center of excellence, into a collaborative setup, where each data domain is co-owned by the respective business function producing the data in its primary business tools.
After all, it is the business operations team that understands the data in context best, and is therefore best placed to communicate and provide data products as a service to other data consumers.
What is a Data Product and What Defines a Data-Products-as-a-Service Model?

1. Data product are a team sport
The data team partners with business operations to tackle specific problems using data.
2. Ownership and support
Data products have an owner, support, service-level agreement (SLA), and clear definition.
3. Shared responsibility
Data products have an SLA from the entire data domain team, not just the data engineer.
4. Bi-directionality
Data-products-as-a-service flow is bi-directional, from the domain data team to the company and back.
5. Integrate domain expertise
Domain expertise is blended directly into the data products themselves.
6. Provide data insights, not just raw data
Data product team members have more business functional experience for their data products, and are responsible for providing insight as opposed to rows and columns.
7. Focus on reliable and quality data
Data-products-as-a-service fuses a service-oriented business partnership focusing on value with a product-oriented SLA focusing on reliability and data quality.
To successfully implement Industrial DataOps, it’s essential to move from a conventional centralized data architecture into a domain data architecture (or data mesh). This solves many of the challenges associated with centralized, monolithic data lakes and data warehouses. The goal becomes domain-based data as a service, not providing rows and columns of data.
For domain data architecture to work, data product owner teams need to ensure their data is discoverable, trustworthy, self-describing, interoperable, secure, and governed by global access control. In other words, they need to manage their data products as a service, not as data.
3.Your Data Needs to Speak Human
The key to creating value from data lies in data context and interpretability by data consumers in business operations, not in the collection of more data.
Confronted with an exponential rise in data volume, velocity, variety, and value creation expectations, enterprises large and small are rushing to upskill their workforces to become better data consumers—or to be more data literate. Gartner formally defines data literacy as “the ability to read, write and communicate data in context,” more informally expressed as “Do you speak data?” Data literacy includes an understanding of data sources and constructs, analytical methods and techniques applied to data, and the ability to describe the use case applications and resulting value.
In industry, most of our production and maintenance data consumers—those at the industrial AI revolution front line—are subject matter experts with deep domain, and domain data, expertise. But they are not data engineers, database specialists or solution architects. Nor should they have to be.
To deliver data literacy at scale and across data domains, it is our data management infrastructure that needs to rise to the occasion and accommodate the growing demands of the new data consumers. This acknowledgement lies at the heart of Industrial DataOps.

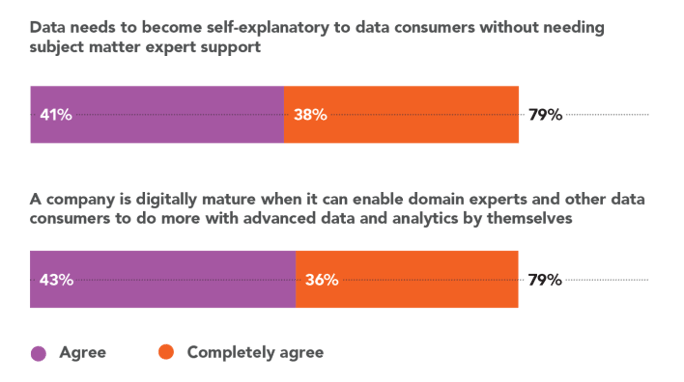
There is a growing realization of this fundamental truth. Research shows that 79 percent of industrial leaders across IT and operations agree that data needs to become self-explanatory to data consumers without needing subject matter expert support. In other words, it is the data that needs to speak human, not vice versa.
“Data has no value unless the business trusts it and uses it. CDOs and data stewards are responsible for working with the business to define the success factors and ways to measure the ability to meet these expectations.”
Forrester
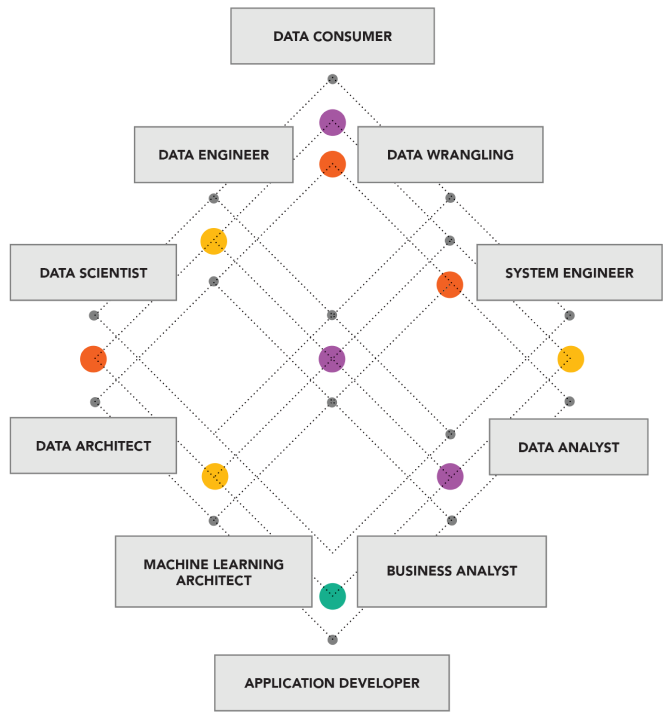
To achieve this level of true data literacy, it’s critical to think in data products and to execute in data domains (see Principle 2. above).
It is equally important to fully embrace AI-enhanced active metadata curation, leveraging advances in neuro-linguistic programming (NLP), optical character recognition (OCR), computer vision, trained ontologies, and graph data models to facilitate increasingly automated IT/OT/ET/X data contextualization for intuitive human as well as programmatic data discovery and use.
Industrials will see ten times higher returns from their investments in metadata than in data itself.
Metadata can be defined as “any data that is used to enhance the usability, comprehension, utility, or functionality of any other data point.” Gartner (2021). The State of Metadata Management: Data Management Solutions Must Become Augmented Metadata Platforms. [26 Mar 2021]
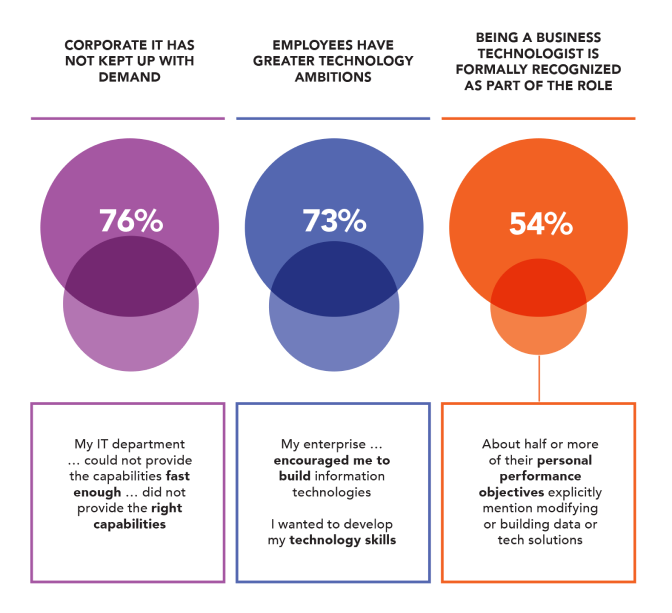
4.Business Technologists Are Your Data Heroes
Your data product manager and data customer target persona is the business technologist, not the data engineer. True digitalization happens outside your digital center of excellence. It happens in your core business operations by the actions of a new class of business-technology hybrids called business technologists.These line-of-business residents are already growing impatient with a lack of Industrial DataOps capabilities, which they need to support self-service discovery and data orchestration from multiple sources.
Such capabilities will enable them to make better decisions and increase their competitiveness. At the same time, industrial application developers crave trusted, consistent, and real-time data to build modern cloud-to-edge microservice applications using APIs, and they too increasingly reside within business operations.
As new data consumer roles such as business technologists increase in popularity, corporate IT is under increasing pressure to deliver faster and more autonomous access to intuitive data products as a service.
Self-service business domain empowerment is of course good news for the business of IT, and it offers an attractive recruitment route for domain data product collaborators as discussed in Principle 2. above.
Of course, the Industrial DataOps platform alone is not the full answer, not even with business technologists paving the way to the next segment of industrial data consumers. It needs to be complemented by enterprise data dashboarding and low-code application development capabilities. Fortunately, both are much more readily available across industries at present.
Finally, to build trust and collaboration across IT and business, don’t refer to your operations subject matter experts as citizen data scientists. They are domain experts. They can also be your best business partners for domain data product delivery as well as championing business technologists. What they are not is “citizens.”
Adapted from Gartner 2020 Digital Friction Survey (2,015 business technologists)
5.Autonomous Industry Is Your North Star
The goal of Industrial DataOps is autonomous industry, not universal data availability or better data engineering.
Industrial DataOps is not only timely and valuable now; it is foundational data infrastructure for the future. This is because the data-driven operations capabilities it provides are equally necessary to achieve the goal of autonomous industry, the promise of Industry 4.0.
This should always be your guiding target, your true north star.
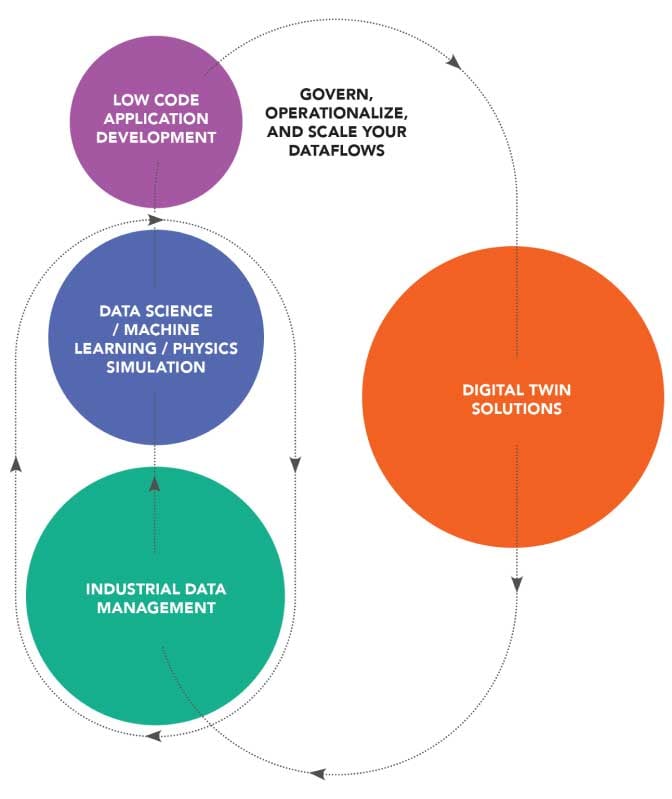
Fig. 16 shows how Industrial DataOps capabilities plug into the industrial transformation journey toward autonomous industry.
Without a robust foundation of Industrial DataOps, trust in data, data models, and data-driven recommendations remains low, resulting in an inability to progress beyond the first or second level of data-driven operations improvement.
If fully autonomous decision-making with closed-loop intelligent production systems as the north star, paving our way there is already well underway, and requires largely the same core technology capabilities.
Industrial DataOps is key to crossing the chasm from simply reporting data to data-driven operations:
- Visualize existing data and put it into context.
- Users interpret information via graphs, dashboards, and make qualified decisions based on available data.
- Enrich the existing data and create recommendation models with actionable advice.
- From simple implementation of known equations to anomaly detection and machine learning.
- Humans evaluate output and make qualified decisions based on the recommendations.
- Advice is delivered to the right persona via a defined process.
- Users are prompted with advice about impending issues and how to proceed. Persona-based content can be delivered through virtual assistants, to provide status and actionable next steps.
- Integrate models directly with selected systems to trigger automatic actions.
- Enable closed-loop integrations with no human interaction.
6.Old Technology Stacks Do Not Work
Executive support, a transformation mindset, and upskilling of people are all needed. Without the right new tooling however, they remain ineffective.
Although they affect the whole enterprise landscape, the disruptive potential of technologies such as AI, cloud computing, and inexpensive data collection is now disproportionately impacting many industrial sectors. These were traditionally insulated from disruption by heavy regulation, low threat of new competition, and extreme capital intensity. Not any more.Power and utilities is perhaps the sector experiencing the greatest disruption. Organizations face a perfect storm of ESG and activist capital allocation, societal sustainability pressure, renewable energies, distributed energy resources (DER), and the rise of electricity prosumers.
Compounding these challenges, the sector is largely reliant on very outdated software technology architecture designed for closed site-level control in a largely static environment.To not only adjust but to thrive, energy companies are aggressively rethinking their data and analytics architectures for the next decade, one set to be defined by constant change, collaboration, real-time data, and innovation.
Despite such profound business environment and technological change, there can sometimes be a tendency to downplay the role that new software technologies need to play, and resort to common executive phrases such as:
“The technology is readily available, it is the change management and people organization that remains challenging.”
“Before we start to address the technology side, we need to thoroughly assess and plan for cultural change implications.”

The idea that cultural change and mindset should be prioritized over technology is simply not true. As the change enablers disrupting our industries are all profoundly technology-led, we need to start with the technology—or address it in parallel at a minimum. Executive support, a transformation mindset, and upskilling of people are all needed. Without the right new tooling however, they remain ineffective.Changing processes or behaviors without the tools to do so—the concrete engines of change—is simply too abstract and disconnected, particularly from the engineering mindset. Technology disruption does, in fact, start with the technology.
So how do you go about finding the right technology stack to power your Industrial DataOps? Figure 15 provides a summary of key features that a domain data consumer-focused digital platform should provide.
In the Appendix (Industrial DataOps RFP Guideline) you will find a comprehensive list of questions to aid formal evaluation and selection of Industrial DataOps software. The appendix covers the entire spectrum of considerations in detail, from use cases and past successes, to solution architecture, to security and software maintenance. It is intended as a complete guide and toolkit to support requests for proposals (RFPs) and similar procurement processes. Here, we have distilled this down to a core set of five key questions to get you started.
Five Questions Industrial Companies Should Ask Before Purchasing Industrial DataOps Software
Industrial software finds its home at the crossroads of the IT and operations worlds. Any software purchase affects both. This means that it’s essential to uncover the needs and requirements of both parties, keeping them informed, involved, and aligned throughout the software procurement process.
You may be making a software purchase to solve a specific problem you have now, but it’s important to think bigger. Software that solves a single use case, be it predictive analytics for gas turbines, or production optimization for certain wells in a field, is an easy fix.
But software that scales to include more turbines or even hundreds of wells across multiple fields is another thing entirely. During your purchasing process, it’s important to look ahead to emerging needs, even a year or two down the road, and ask yourself: can this software meet them?
When it comes to software, seeing really is believing. PowerPoint slides and talented salespeople can only tell you so much. A demo will show you. It’s within your rights to request this kind of real-life proof, to get a taste of what that technology can do for you.
The harsh reality is that no software available today will be able to fit your needs perfectly. Out-of-the-box software products may meet about 80 percent of your needs.
And while this may not cover all your requirements, it’s important to remember that, with the right software partner, it does mean that four out of every five of your requirements will be met within six months.
This is a far better option than holding out and waiting for the “perfect” solution (that may never come), or building something completely bespoke in-house that you will need to maintain indefinitely. This requires smart adaptability and a willingness to go for “good enough” when it comes to software. Over time, and most likely faster than you think, you can go from good enough to game-changing.
Pricing software is not copy-and-paste from the pricing of a pump. It requires an entirely different approach. Software is a product, and it is priced as such, rather than charging by hours based on level of experience. Once you know the product price, ask about scalability, as future needs are bound to arise. Discuss with your vendor a pricing model that removes friction at later stages, for the time when you are ready to scale solutions across the rest of the organization.For a complete list of essential questions and criteria, see the Appendix (Industrial DataOps RFP Guideline: Questions to Aid Evaluation).
7.Quality Is King
Speed matters, but running fragile solutions leading to failures in production simply does not work in industry.
In 2014, even Facebook changed its motto for developers from “Move Fast and Break Things” to “Move Fast With Stable Infra”. They feared that they may have been moving too fast to see where they were going clearly. As Mark Zuckerberg said, “What we realized over time is that it wasn’t helping us to move faster because we had to slow down to fix these bugs and it wasn’t improving our speed.”

Such caution may have been novel in the world of digital technology giants, but for the world of industry it is a well established necessity. Across asset-heavy industries, a whole range of weighty factors mean that the ‘fail fast’ mantra is rarely appropriate.
These factors include the risk of high-profile failures and outages causing serious public impact and lasting reputational damage, the cost of machinery and equipment, employee health and safety, and potential environmental impacts.
“We can’t operationalize unless we trust the data. If something fails and we can’t provide auditability we are finished as an industry.”
Digital Operations Manager, Aker BP
For most of the software development and data engineering era (a relatively short one when compared to the industrial organizations being served), speed and quality have been in opposition. This is especially true when working with complex data dependencies in a real-time environment. Dependable, secure, observable data pipelines across batch and streaming data sources, as well as pragmatic data quality fitting the use case being developed, have long been aspirational but not achievable—at least not without majorly sacrificing speed.
With Industrial DataOps, organizations can achieve both quality and speed by moving the direct responsibility of risk and data quality to the development teams who understand the solution context best. This approach enables ambient data governance rather than slow, rigid, and costly centralized master data management.
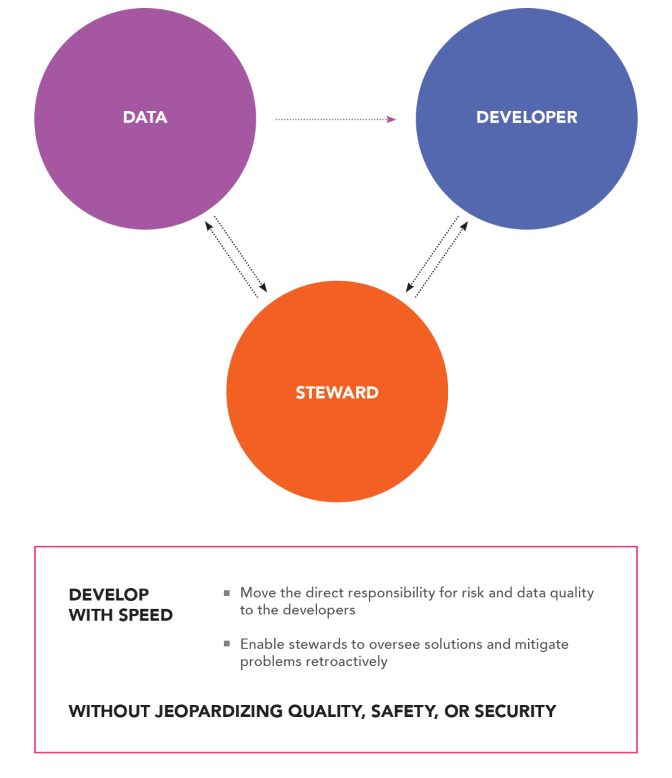
Industrial DataOps requires that organizations make use-case-relevant data quality controls easy for development teams consisting of business technologists, rather than data quality specialists. This means seeking Industrial DataOps tools that provide most common data quality models pre-built and easy to apply in the natural application data template definition phase directly.
“The diverse and distributed nature of IoT solutions means that a traditional, one-size-fits-all, control-oriented approach to governance is insufficient. Organizations need to be able to apply different styles of governance for different types of data and analytics.”
Previous chapter
Extracting Value From DataNext chapter
Industrial DataOps in Action